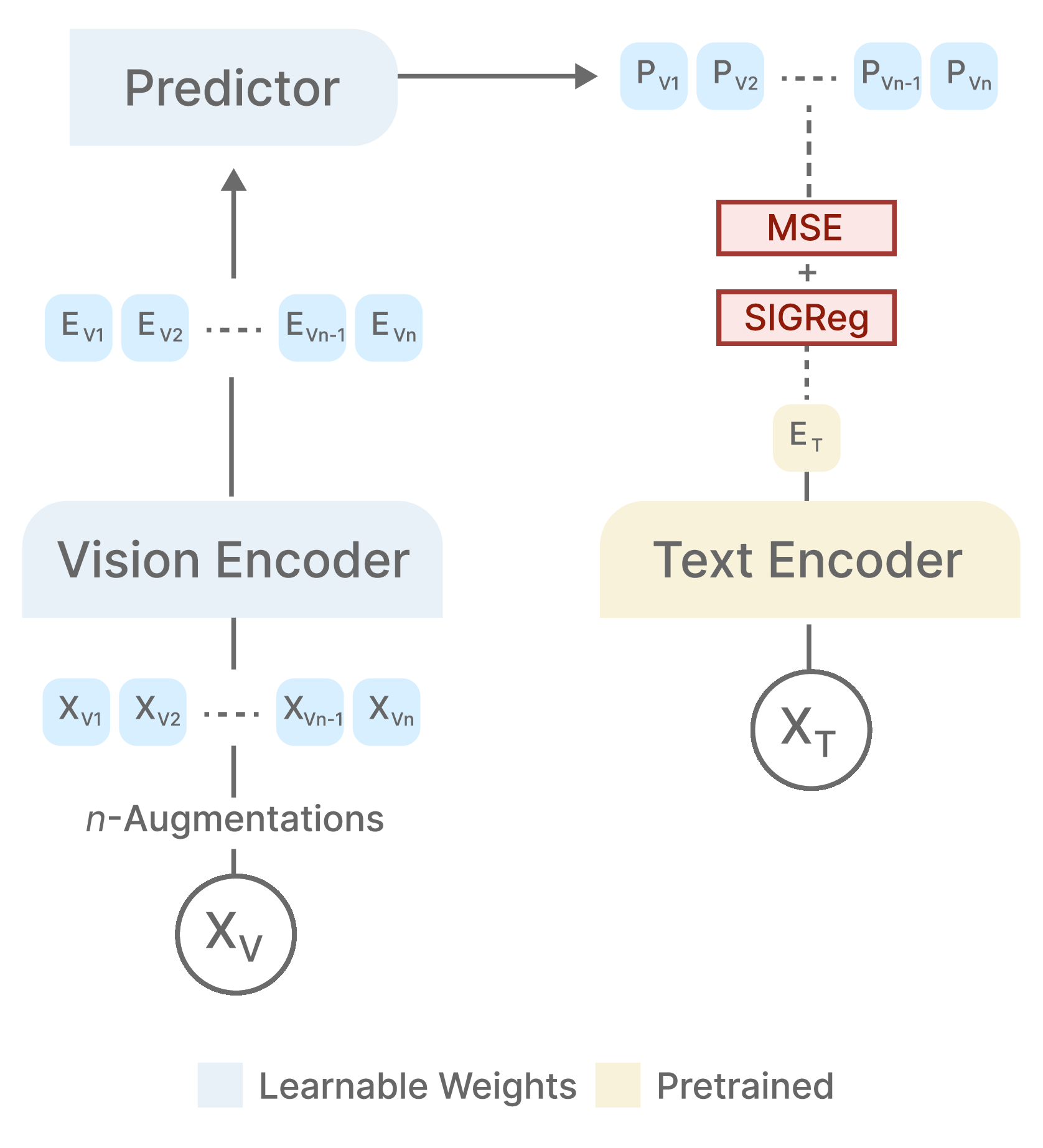
Vision-language models have transformed multimodal representation learning, yet dominant
contrastive approaches such as CLIP require large batch sizes, careful negative sampling,
and extensive hyperparameter tuning. We introduce NOVA, a
NOn-contrastive Vision-language
Alignment framework based on joint embedding prediction with
distributional regularization.
NOVA predicts frozen, domain-specific text embeddings from augmented image views and
enforces an isotropic Gaussian structure through Sketched Isotropic Gaussian
Regularization (SIGReg). This removes negative sampling, momentum encoders, and
stop-gradients, reducing the training objective to a single trade-off parameter.
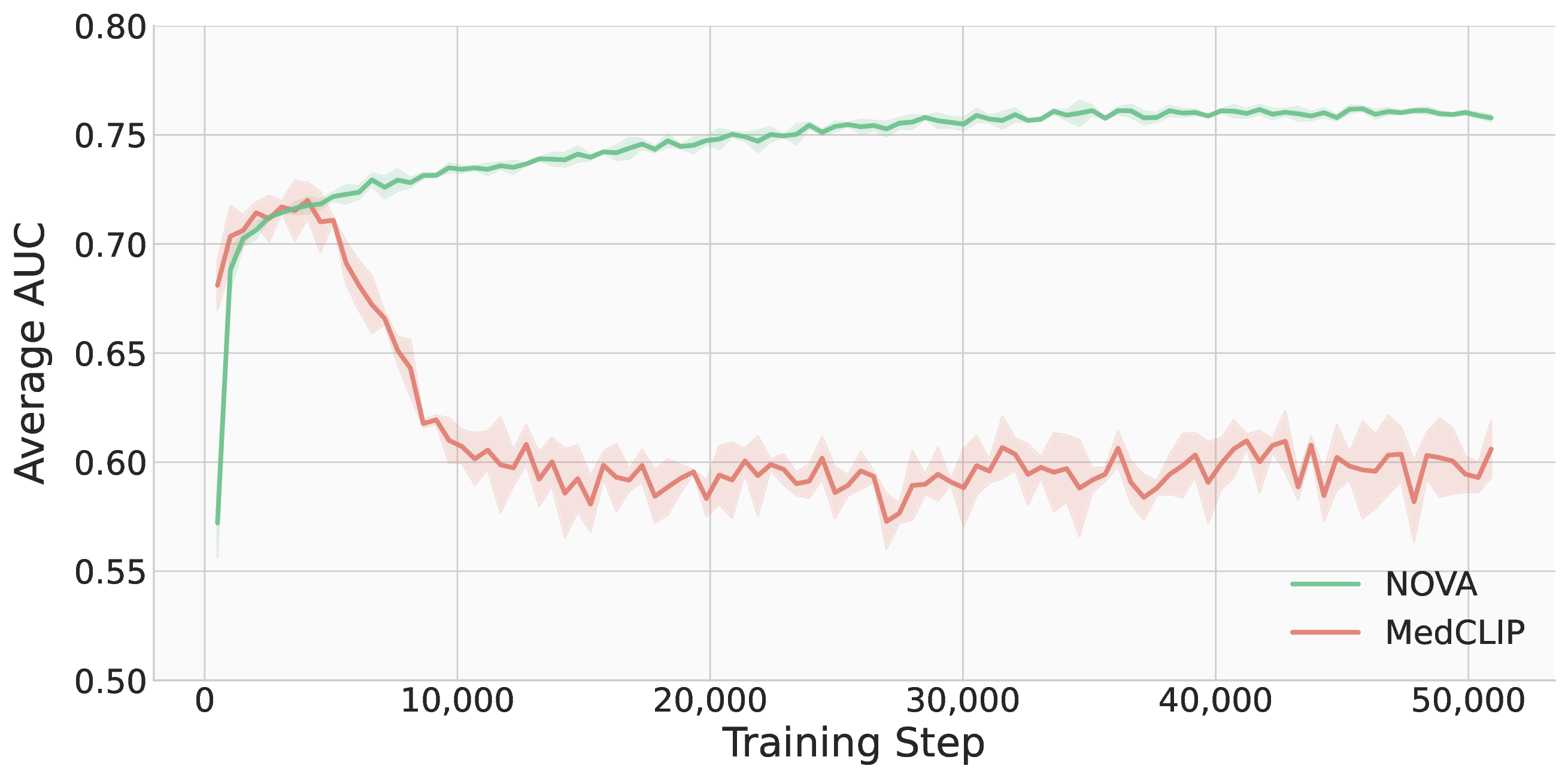
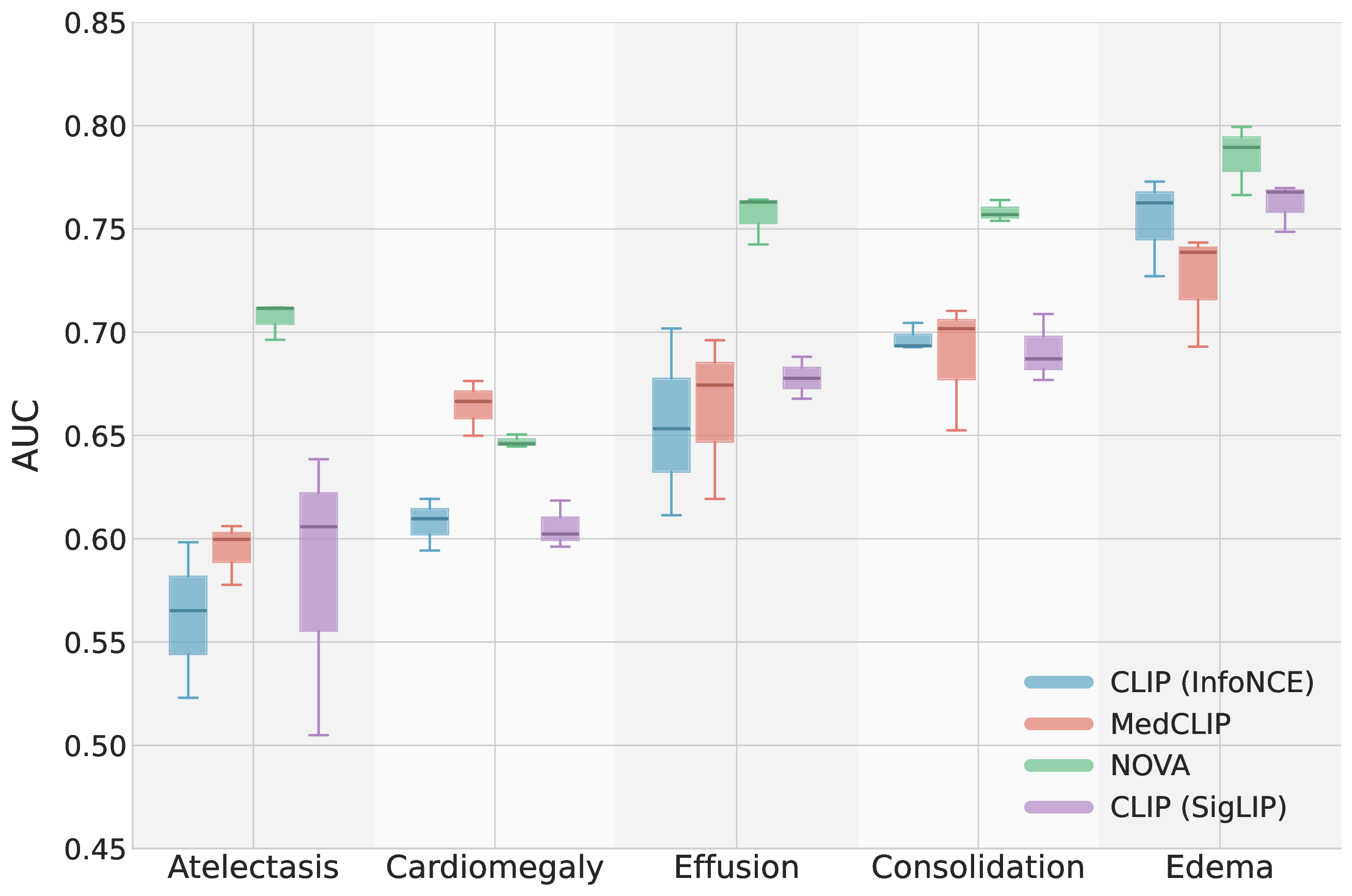
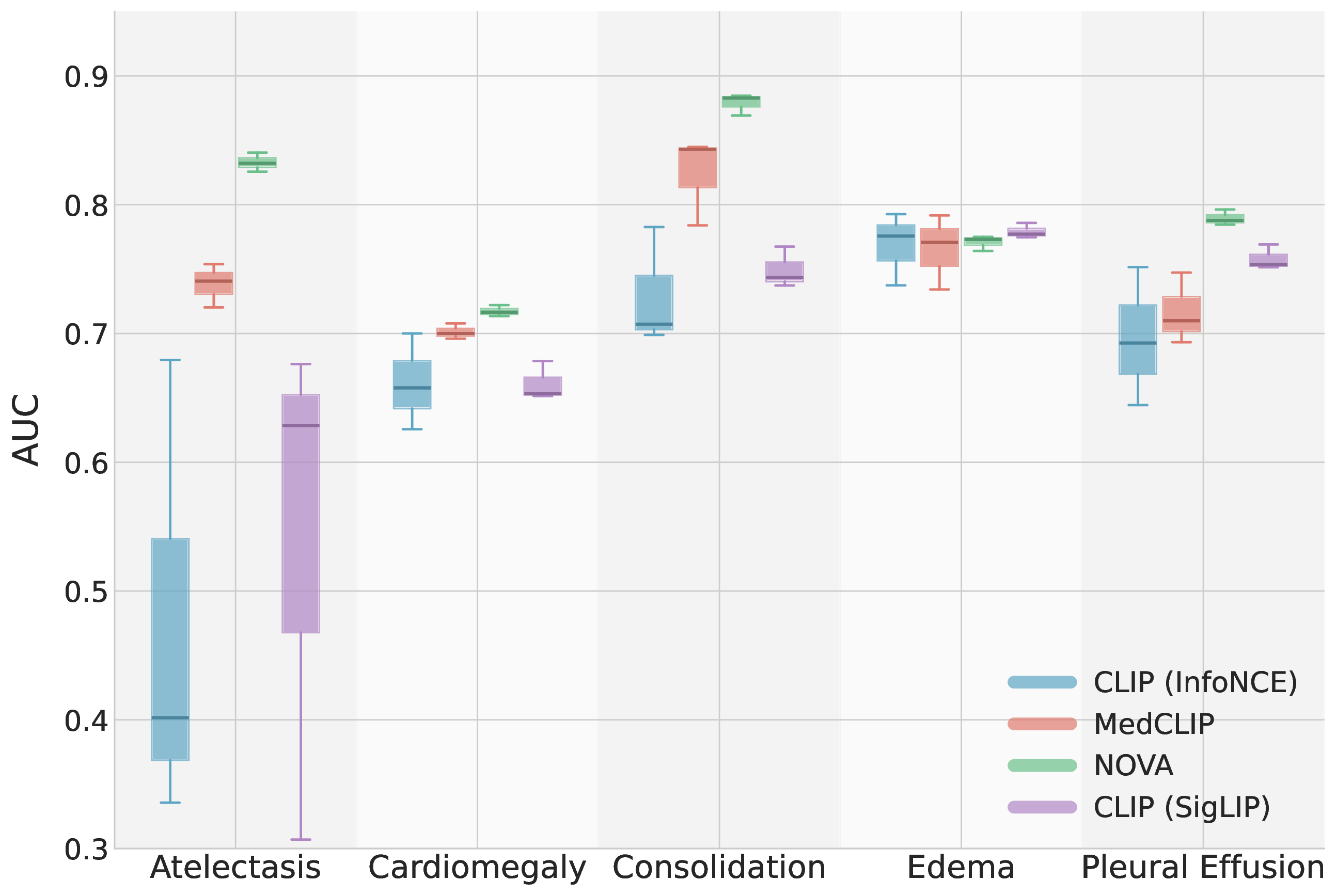
On zero-shot chest X-ray classification, NOVA outperforms CLIP and MedCLIP-style
baselines across MIMIC-CXR, ChestX-ray14, and CheXpert while showing substantially
more consistent training runs.